

In 2013, Google recorded indexing 30 trillion pages. Barely 3 years later, that number climbed by another 100 trillion—bringing the indexed pages on Google to 130 trillion.
Now it’s 2022: How many pages do you think Google has indexed? Pretty confident a few hundreds of trillions of pages would have been indexed since 2016.
Contrary to most assumptions, these numbers don't reflect the total number of pages online—instead, it’s the number of pages Google’s aware of.
All of this leads to a series of questions on how Google crawls and indexes web pages.
Before understanding Google’s process, let’s discuss search engines and how they work.
How Do Search Engines Work?
Search engines work by crawling trillions of web pages to identify different pieces of web content—videos, images, texts, etc.—and indexing them based on related search terms.
For search engines to function effectively, three core parts are responsible.
Web Spiders/Crawlers
These are search-engine bots, mostly called spiders or crawlers, that scour the internet looking for new or existing publicly available content. Once the crawlers find a new piece of content, they collate the required information needed to index or “store” them in simple terms.
Search Index
This is a record of all crawled web content. With this, search engines can map search queries on four principles:
- Keywords
- Page content
- Page context
- Content quality
Search Algorithm
This is a unique formula all search engines use to grade content relevance to search queries.
Search engines work by crawlers enabling the indexing of all web content and the algorithm grading the quality of each piece of content.

This process is the same for all search engines— Google, Bing, DuckDuckGo, Yandex, CC Search, SwissCows, StartPage, Wiki, etc. For this post, let’s focus on the big guy, Google.
How Does Google Work?
Google is a fully automated search engine that uses web crawlers or spiders to analyze trillions of web content to serve users based on their search queries. According to Matt Curts, Content Quality Engineer, Google:
“The first thing to understand is when you do a Google search, you aren’t actually searching the web, you’re searching Google’s index of the web… or at least as much of it as we can find.”
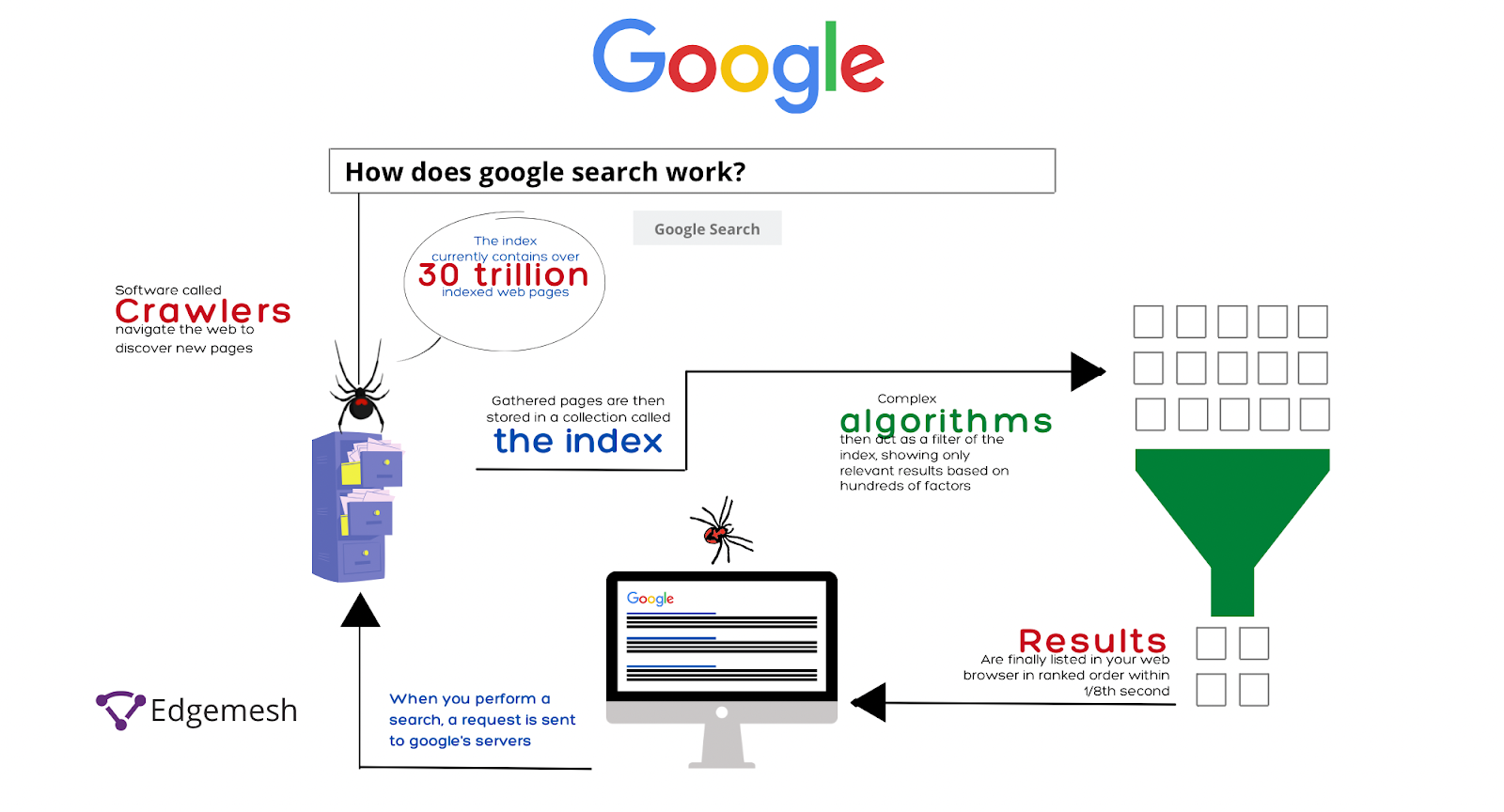
For content to be seen by Google and shown to others, the content has to be crawled and then ranking begins.
What is Google Crawling?
Google crawling is a process of discovering new content on the internet. The most common method for Google to do this is following hyperlinks of already crawled web pages to new ones.

Since the crawling process is never-ending, the software continues crawling pages already indexed to replace dead links and redirects.
The Complete Guide to Dynamic Rendering and Its Impact on SEO
Often, when you change links to your already crawled web pages, Google might not immediately pick up on it—so it’s better to manually submit your sitemap to Google.
Now that we’ve covered crawling, let’s talk about the next phase—Google indexing.
What is Google Indexing?
Google indexing is storing content crawled by the Google crawlers into the database.
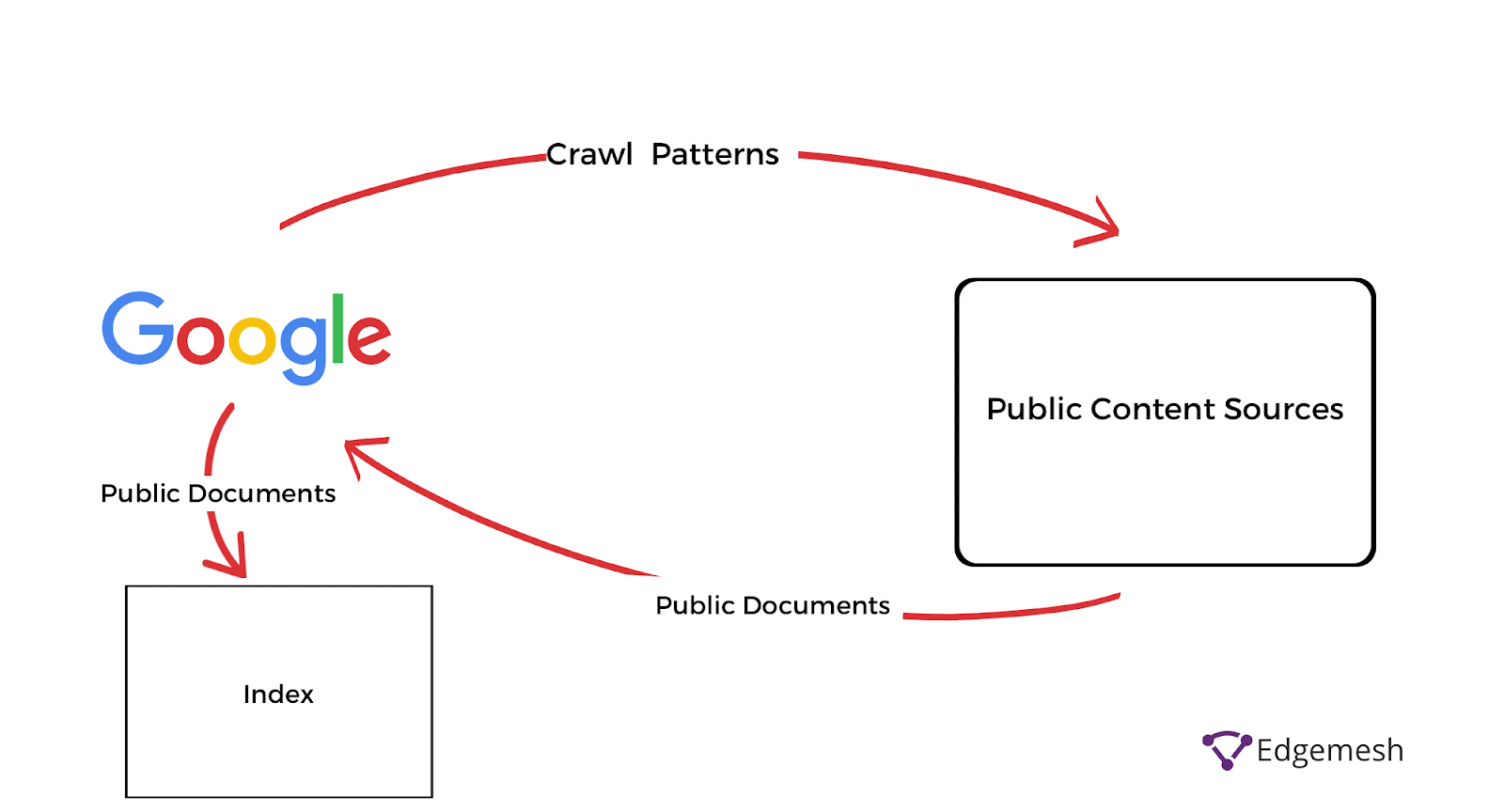
When the Googlebot (crawler) finds new content on the public databases, it transfers it to the indexing phase—which sorts out the transferred content into different categories based on relevance.
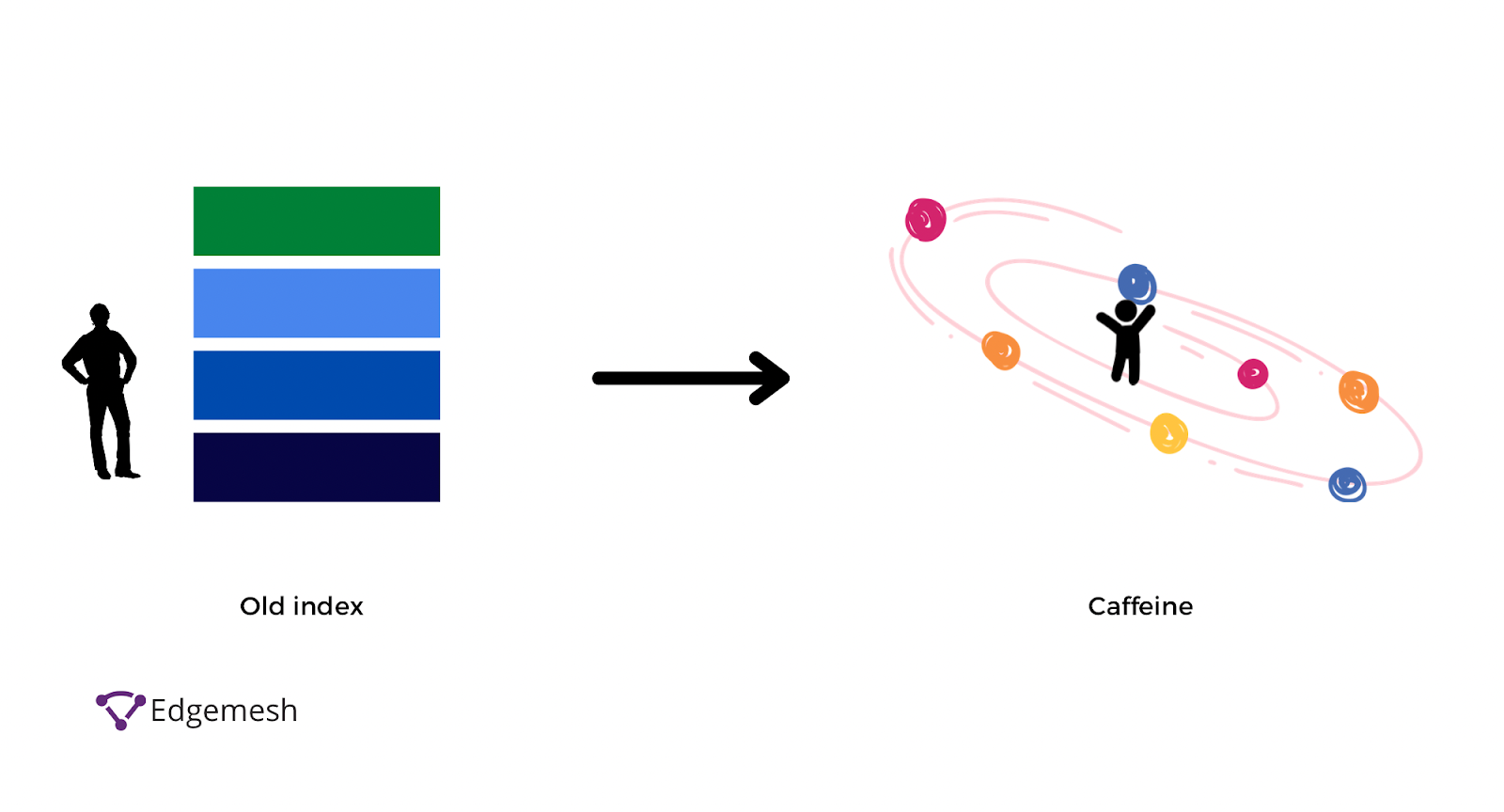
Although this process is orderly and provides almost accurate results, it didn’t deliver as high as users expected. So, in 2010, Google released an update on their indexing system, called Caffeine.
According to Google,
“Our old index had several layers, some of which were refreshed at a faster rate than others; the main layer would update every couple of weeks. To refresh a layer of the old index, we would analyze the entire web, which meant there was a significant delay between when we found a page and made it available to you.
With Caffeine, we analyze the web in small portions and update our search index on a continuous basis, globally. As we find new pages, or new information on existing pages, we can add these straight to the index. That means you can find fresher information than ever before—no matter when or where it was published. Caffeine lets us index web pages on an enormous scale. In fact, every second, Caffeine processes hundreds of thousands of pages in parallel.”
In comparison, this new update provides 50% fresher results than the last index system. The basis of this update is crawling and indexing the most current information related to every search query.
But there’s a catch—the goal of crawling and indexing content is to provide results to users’ queries. So it has to be indexed for a page to serve users. How does Google serve these results? Through a ranking system.
What is Google Ranking?
Google ranking is an algorithmic system that analyzes indexed content and sorts through it to return the right result to searchers’ queries. These results show up on SERPs—Search Engine Ranking Pages. The relevance of the content is arranged based on its rank in the system.
Rumor has it that Google ranks content using 200+ factors, but that has not been confirmed.
Here are the 7 Google ranking factors we can confirm Google uses:
- Search Intent
- Page Speed
- Authority
- Linking Structure
- User Experience
- Mobile Experience
- HTTPS Website Security
7 Google Ranking Factors You Need And How They Affect SEO In 2022
If your page checks out in most of these areas, you’ll likely rank high enough after your page is indexed.
Although Google credits its Caffeine update with almost instantly indexing content as soon as it’s published, stats show less than 4% of the entire web is indexed by Google. In another case, Google doesn’t completely index all pages on a website.
In a conversation about how only 20% of a website would be indexed with Google Search Advocate John Mueller, he said —
“The other thing to keep in mind with regards to indexing, is it’s completely normal that we don’t index everything off of the website. So if you look at any larger website or any even midsize or smaller website, you’ll see fluctuations in indexing. It’ll go up and down and it’s never going to be the case that we index 100% of everything that’s on a website. So if you have a hundred pages and (I don’t know) 80 of them are being indexed, then I wouldn’t see that as being a problem that you need to fix. That’s sometimes just how it is for the moment. And over time, when you get to like 200 pages on your website and we index 180 of them, then that percentage gets a little bit smaller. But it’s always going to be the case that we don’t index 100% of everything that we know about.”
This response is obviously for a large website, but what about small websites whose content is also not completely indexed?
According to John Mueller,
“So usually if we’re talking about a smaller site then it’s mostly not a case that we’re limited by the crawling capacity, which is the crawl budget side of things. If we’re talking about a site that has millions of pages, then that’s something where I would consider looking at the crawl budget side of things. But smaller sites probably less so.”
It seems there’s no solution to improving your chances of getting indexed if Google decides not to index your website automatically. So, how do you get your website indexed by Google?
How To Get Your Website Crawled and Indexed By Google Faster
The process of showing up on SERPs is crawl, index, rank. You can’t skip a step.
Since Google might not do all the job for you, an easy way to get them to recognize your website is through your sitemap.
1. Find Your Sitemap
A sitemap is the blueprint of your website showing all web pages and the relationships between all of them. It’s your way to tell search engines like Google the structure of your website to aid in crawling and indexing them.
Good site architecture is essential before submitting your sitemap to google. Using the proper linking structure, you can pinpoint important pages for Google and let the crawler do the rest without constantly re-uploading. You can find your sitemap using different methods depending on how your website is built.
a. Check Your CMS
Fortunately, most CMS providers allow the easy generation of sitemaps for users without technical knowledge.
For example, if you’re using WordPress, installing a plugin like Yoast SEO will automatically generate XML sitemaps and include your site architecture to help Google understand your website better.
Meanwhile, suppose you’re using other CMS like Shopify, Wix, or Squarespace. In that case, you can automatically generate your sitemap by adding— “/sitemap.xml” (without the quotes) — at the end of your site address in the address bar.
Example: https://www.edgemesh.com/sitemap.xml
Which should you give you this when you click on it:
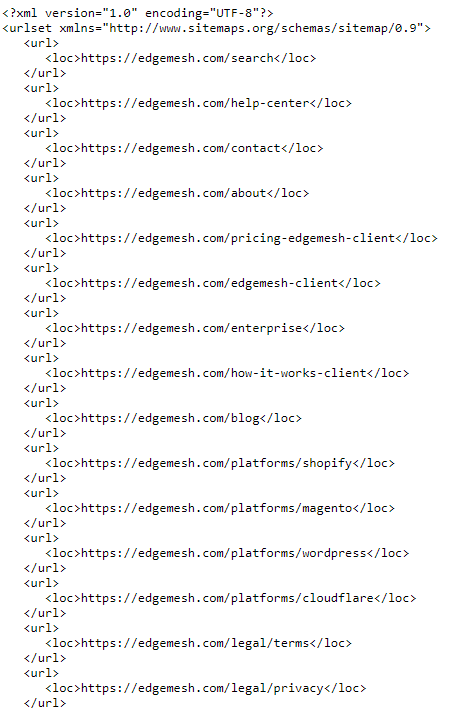
Understanding the sitemaps tags:
- <urlset>—This is the tag the sitemap opens and closes with. Inside it is all your site architecture.
- <url>—This is the parent tag of all URL entries within the <urlset>.
- <loc>—This is the tag containing your domain address.
b. Check Your Robots.txt File
The robots.txt file of your website contains directives for web crawlers to include or exclude web pages from being indexed. Since your sitemap contains the hierarchical structure of your website, it’ll be stored in your robots.txt file, and here’s how to find it:
First, add/robots.txt to your domain.
Let’s use the Apple website as an example—https://www.apple.com/robots.txt.
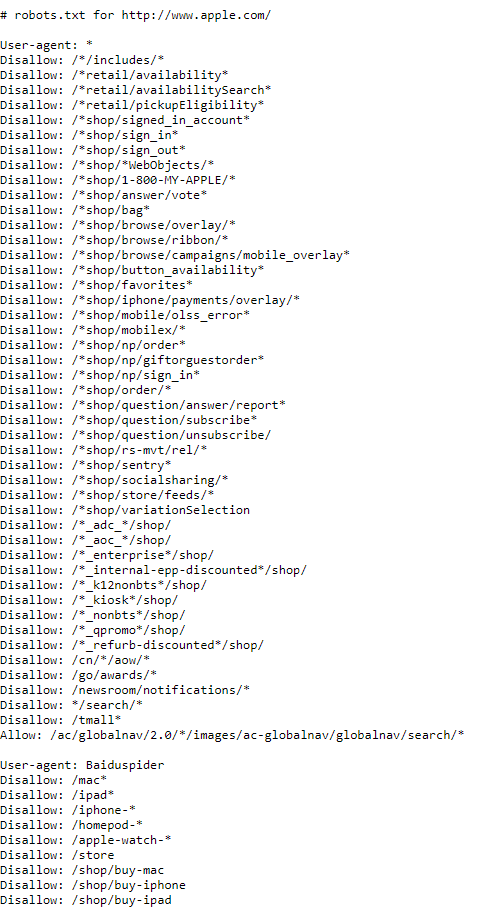
When you scroll further on the page, you’ll get their sitemap and everything in their directives.
And if you notice, there’s a “disallow” tag on some pages. That’s one of the functions of robots.txt. It provides the freedom of dictating to web crawlers which pages you want to be crawled and indexed and which ones you don’t.
2. Submit Sitemap To Google Console
After finding your sitemap, submitting it to Google is the next step.
Here’s a step by step process:
- First, head over to Search Console, and click on sitemaps.
- Next, paste your sitemap address in the “add a new sitemap” section and click submit.
- If it’s successful, it’ll write “success”—and if not, perhaps it’s a wrong sitemap, you’ll get “couldn’t fetch the file.”
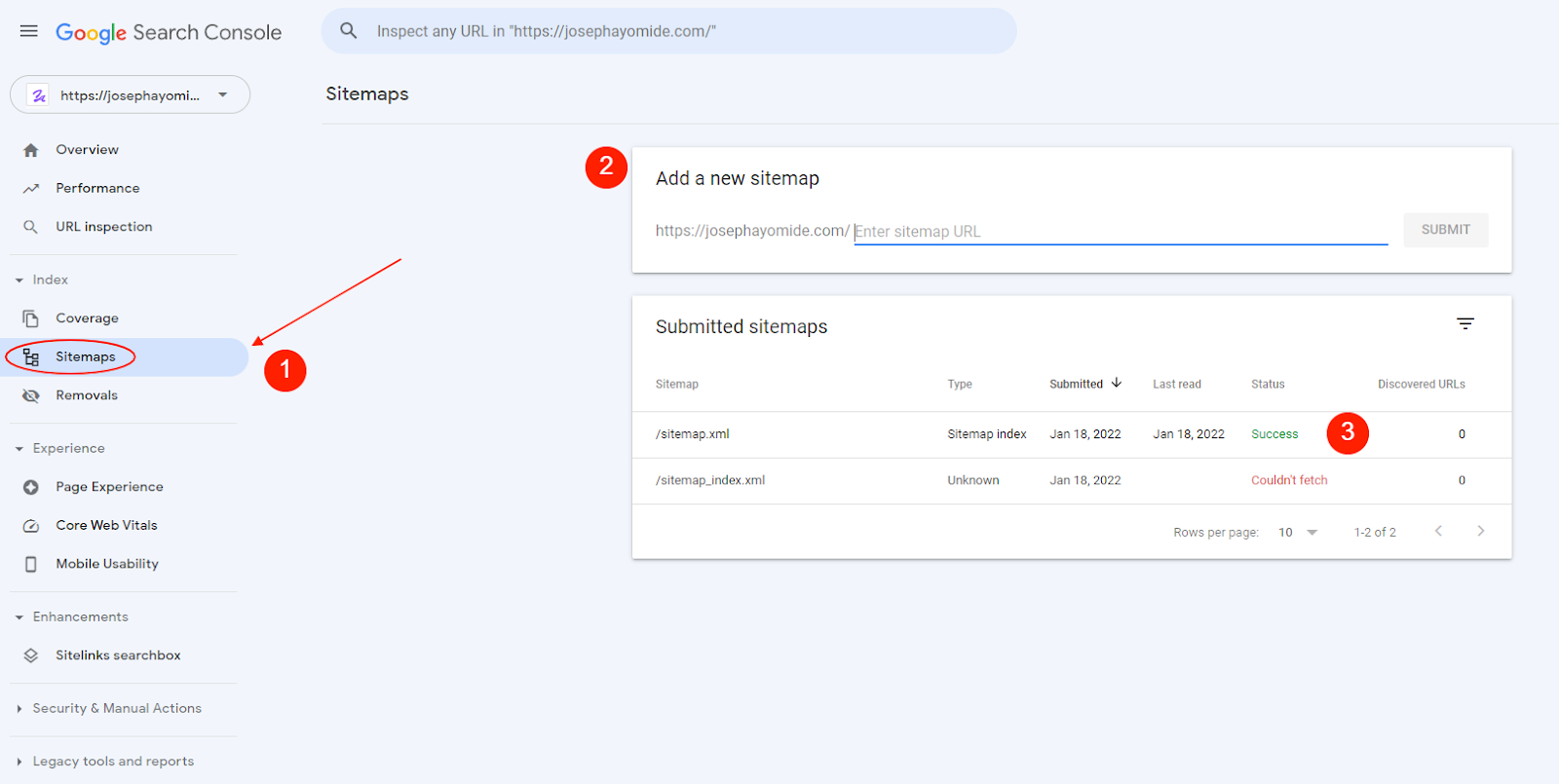
Note: To submit a sitemap on Search Console, you need to set up your property. If you haven’t done that, follow this guide from Google: Add A Website Property On Google Search Console.
Once you submit your sitemap to Google, the Googlebot starts crawling your website and indexing all your content, including old and new content.
What If I Can’t Find My Sitemap?
The short answer is you can build your sitemap if you don’t find it.
How do I build my sitemap?
If all earlier methods failed in discovering your sitemap, then using a third-party tool is your next option. Screaming Frog and Slickplan are two of the best tools to build a sitemap.
Using Screaming Frog
The screaming frog SEO spider is what you’ll use to generate your sitemap. If you have fewer than 500 URLs on your website,the free plan is perfect for most of what you need it for. And if you have more than that, opt for the paid plan at $200.00 per year.
Follow the steps on the website to build a sitemap using their tool properly.
Building A Sitemap With Screaming Frog
Using Slickplan
Building a sitemap on Slickplan is different. With the sitemap generator, you get an interactive interface that lets you visually drag and drop your web page in the exact format in which you want the sitemap.

Call it a visual sitemap—like sketching your house’s blueprint before building.
Slickplan prices start at $8.99 for the basic plan, and it’s what you’ll need to kickstart building a solid sitemap. Here’s a guide from Slickplan on building your sitemap.
Once you get your sitemap sorted out, you’re finally visible to Google and other users.
So, if your content is relevant to a user’s search query, Google will look into their search index, rank it using their factors, and serve up your content.
How Long Does It Take Google To Index A Website?
There’s no definite time for how long Google’s indexing process takes. Some websites, especially small ones with fewer pages, can take as little as an hour or a few hours. The process can take weeks to even months for large websites.
The larger your website, the longer it takes for Google to index them—and vice versa.
How do you know when your page is indexed?
How To Know If Google indexes your Pages
Google provides two options to check if your web pages are indexed.
Using The Google Search Bar
This is the easiest way to check if your web pages are indexed.
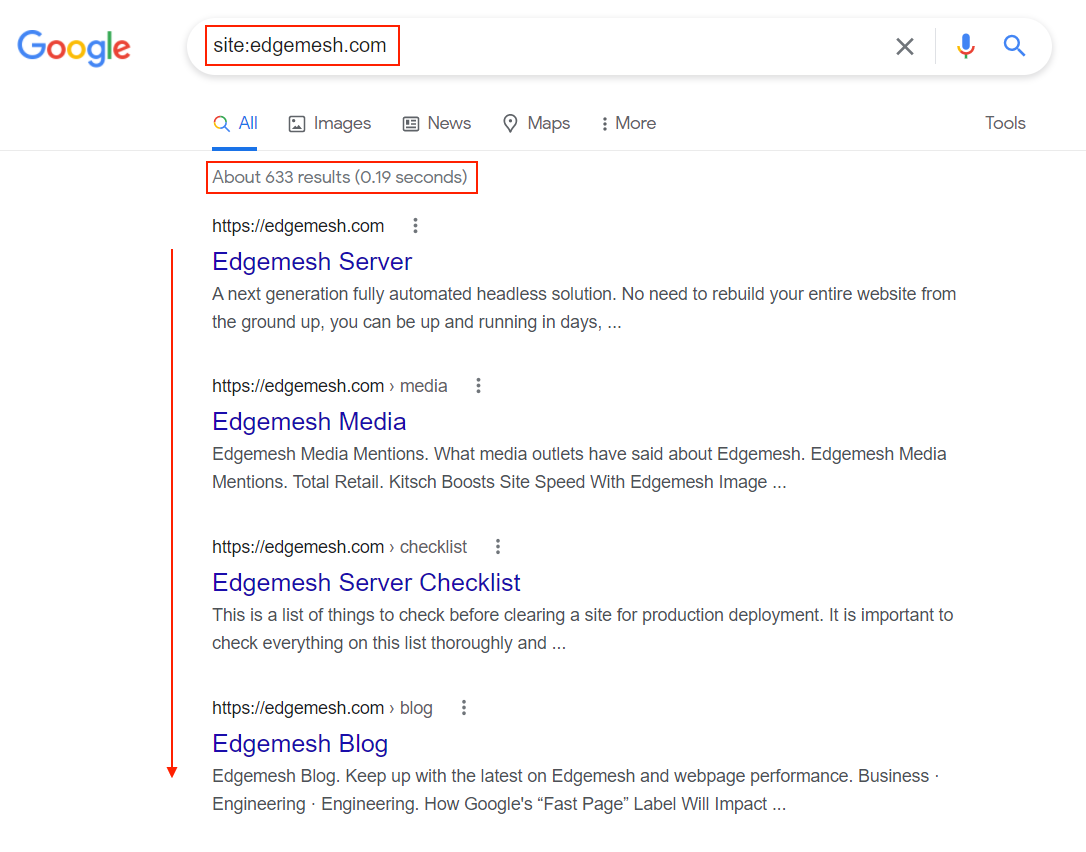
- Go to the Google search bar and type site: website address.
Example: site:edgemesh.com
- You’ll get a list of all your web pages crawled and indexed by Google.
- If you’d like to go deeper, or perhaps you recently uploaded content or changed a page, and want to check if Google has indexed it, do this:
Replace the website address with the exact address of the page you’re looking for.
In our case, we published a page a few days ago and want to check if Google has indexed it.
Example:
site:https://edgemesh.com/blog/7-google-ranking-factors-and-how-they-affect-seo-in-2022
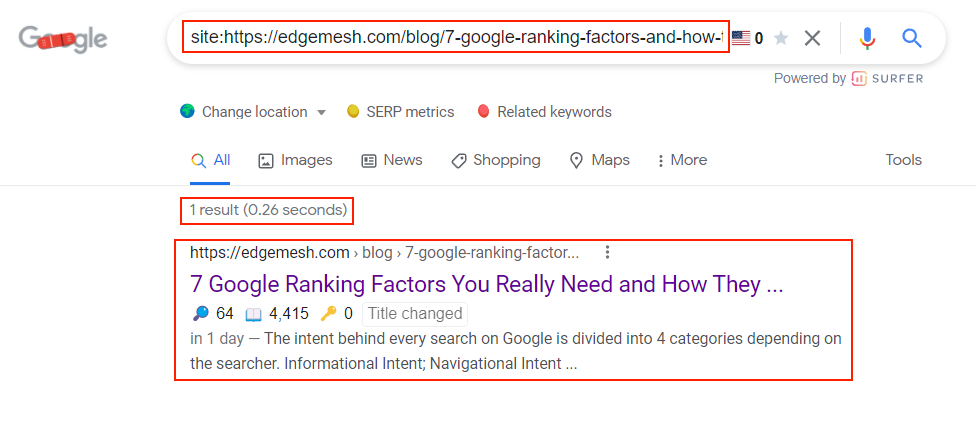
If your page isn’t indexed yet, you’ll get an error like this:

This was our page on the day it was published.
Using the Index Coverage Status
The index coverage status reports the number of discovered or indexed URLs on your website. Using this feature is only available on Google Search Console.
- Go to your Search Console panel and head over to coverage to see your indexed URLs.
Here’s the coverage of a sample website:

Your focus is the valid tab—that’s the number of pages indexed on your website.
Bonus tip about the coverage status: You get 4 tabs indicating pages with:
- Error
These are pages on your website that couldn’t be indexed for some reason. With this tab, you can easily identify pages that the Google crawler has issues crawling and indexing for certain reasons.

- Valid With Warning
This tab is for pages on your website that have been indexed, but there’s an issue for some reason on your end.

- Valid
The valid tab shows you the number of pages indexed on your website. It’s Google’s way of confirming they have your website on their server.
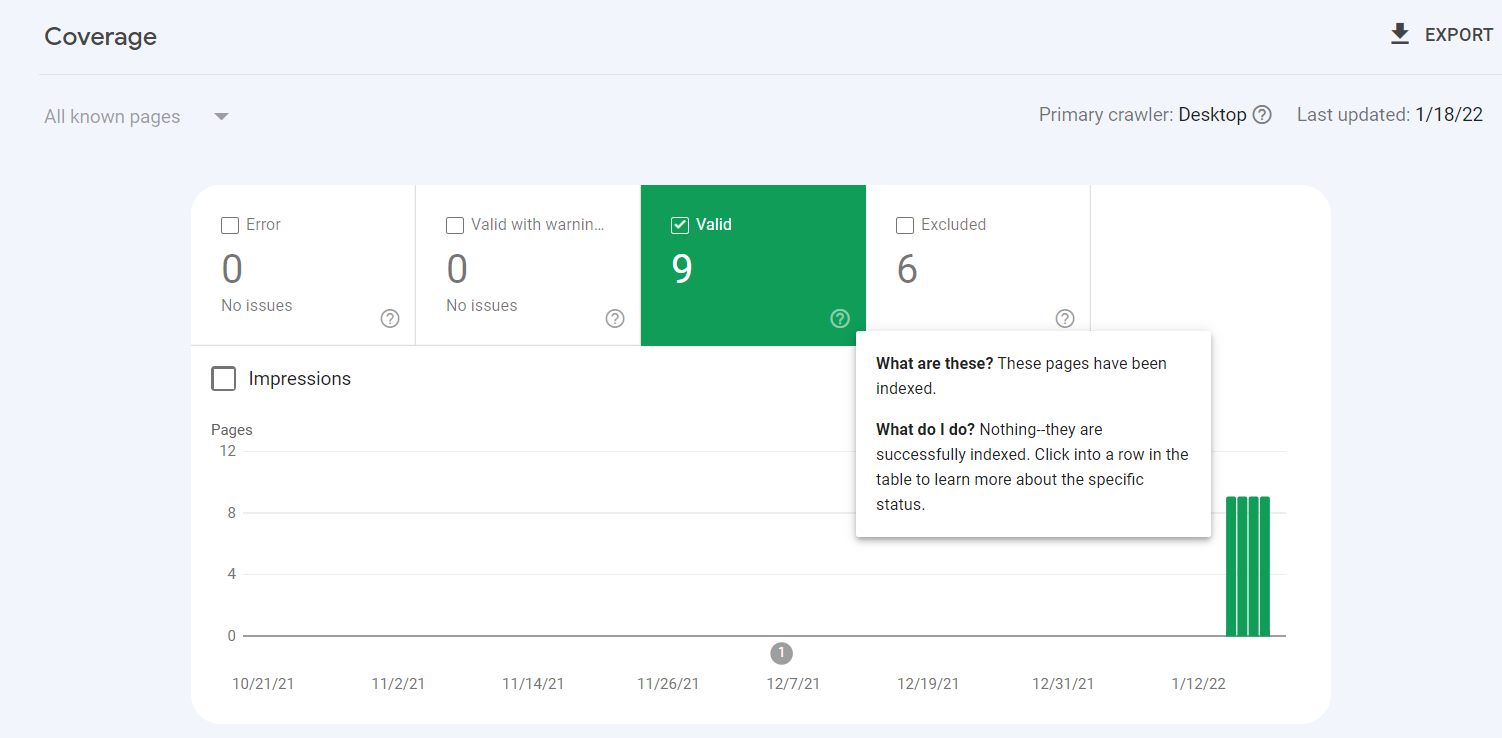
- Excluded
This tab includes the pages you tell the Google crawler not to index on their server.

And that covers it on using the coverage status on Google Search Console.
Another question is: Despite doing it all correctly, what if Google doesn’t still index your website? There are several reasons, but let’s cover the 5 major ones.
5 Reasons Google Isn’t Indexing Your Pages
1. Your Website Does Not Support Mobile-first Indexing
Since Google introduced the mobile-first indexing update, the indexing process has changed.
“Mobile-first indexing means Google predominantly uses the mobile version of your content indexing and ranking.”
This doesn’t mean if your website is mobile-friendly, you automatically qualify for mobile-first indexing. Instead, Google compares the content on the desktop version with the mobile version.
In cases where the critical content shows on the desktop version and doesn’t on the mobile version, the website can’t be considered for mobile-first indexing.
In a conversation on Reddit, John Mueller, Senior Search Advocate at Google, confirms this.

The best solution is to cross-check your site architecture and display it on desktop and mobile.
2. Third-party Robots.txt Plugins
The robots.txt file of your website is a powerful communicator to the Google crawler.
If you have little to no technical know-how, you’re likely to “no-index” your whole website or important pages—or in some cases, make it a private page. The best solution is to find an expert technical SEO specialist to help you fix it.
If you want to fix it, go to your root directory where your robots.txt is located and make these changes.
Change this:
User-agent: *
Disallow: /
To this:
User-agent: *
Disallow:
Removing the forward-slash (/) unblocks all pages from the root folder on the site. You can use the no-index tag in your script to block Google from indexing some pages on your website.
3. Constant Page Redirects
Page redirects are one of the biggest problems in successfully indexing your website—especially if the page no longer exists.
Some common reasons for redirects include:
- Change of domain
- Change in permalink structure of your website
- Mistakes in title and URL
- Changing target keyword after post publishing
- Wrong backlinks
- Moving from HTTP to HTTPS.
When the Google crawler tries indexing your website and finds something like this, it sends a bad signal—potentially the 404 error page.
When it comes to redirects, there are different types, and each has different meanings and uses. For this, we’ll cover the 3 main redirects.
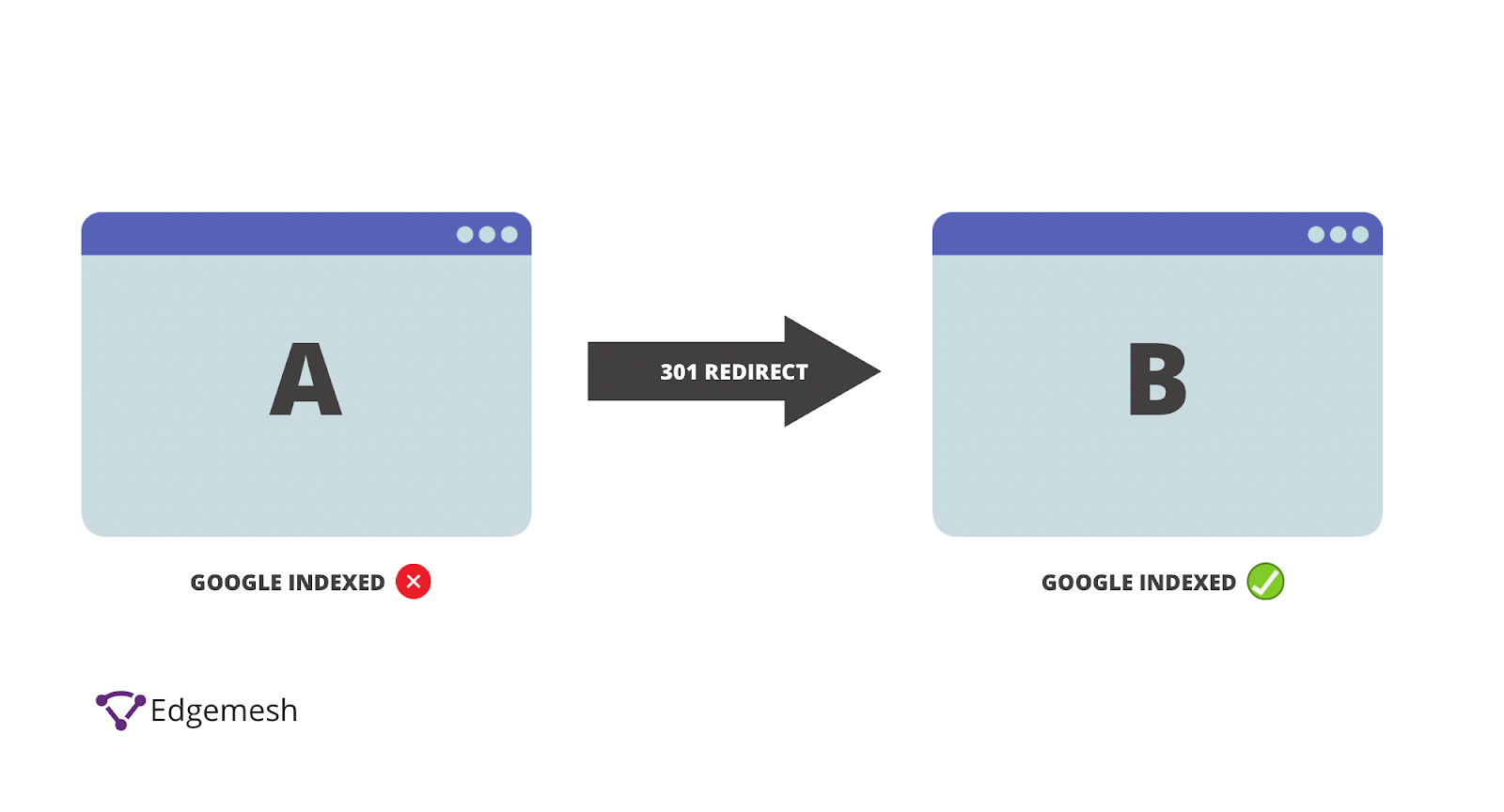
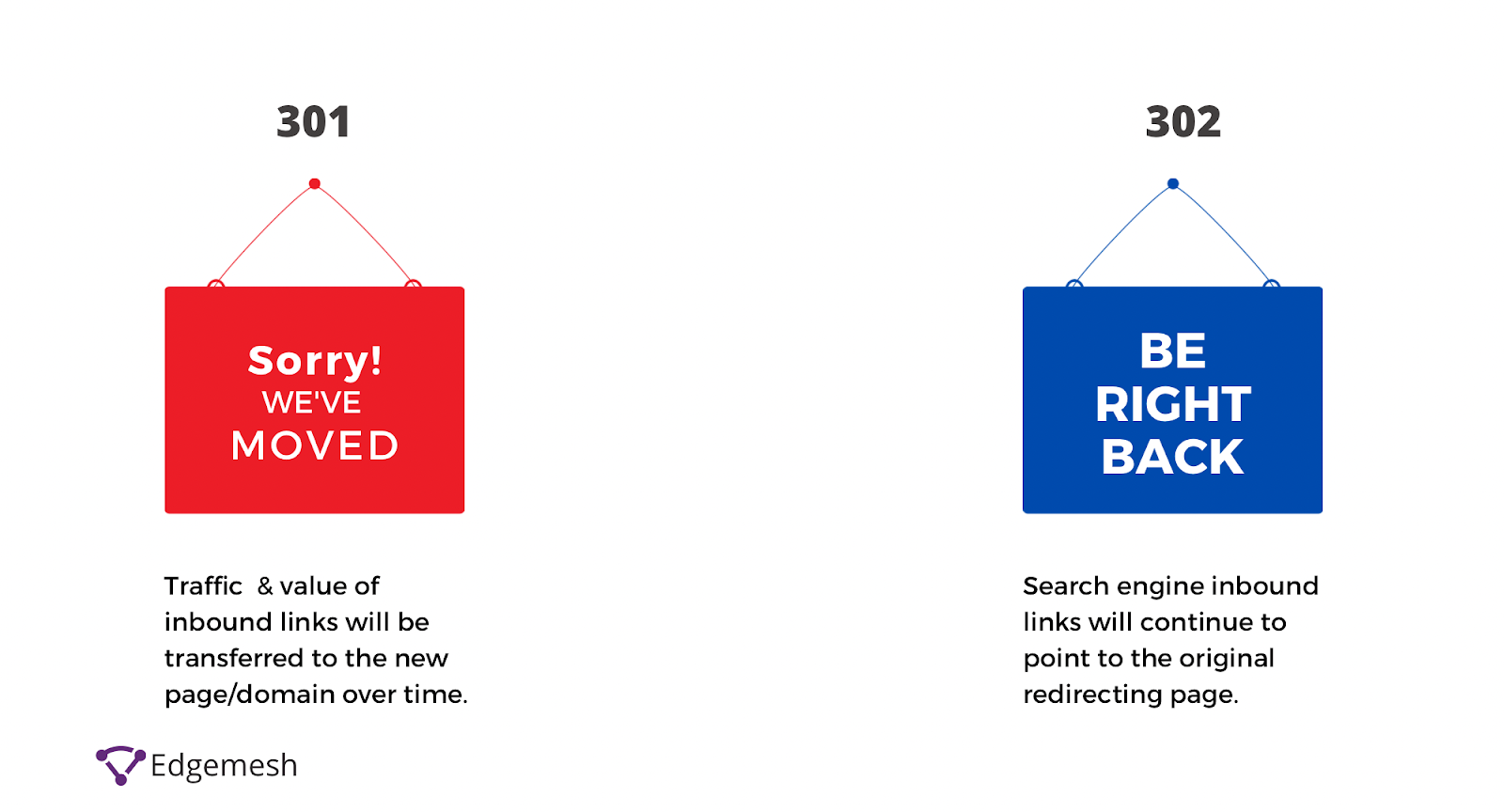
301 Redirect
The 301 redirect means the page has permanently moved to a new location—and can be found at/with the indicated address.
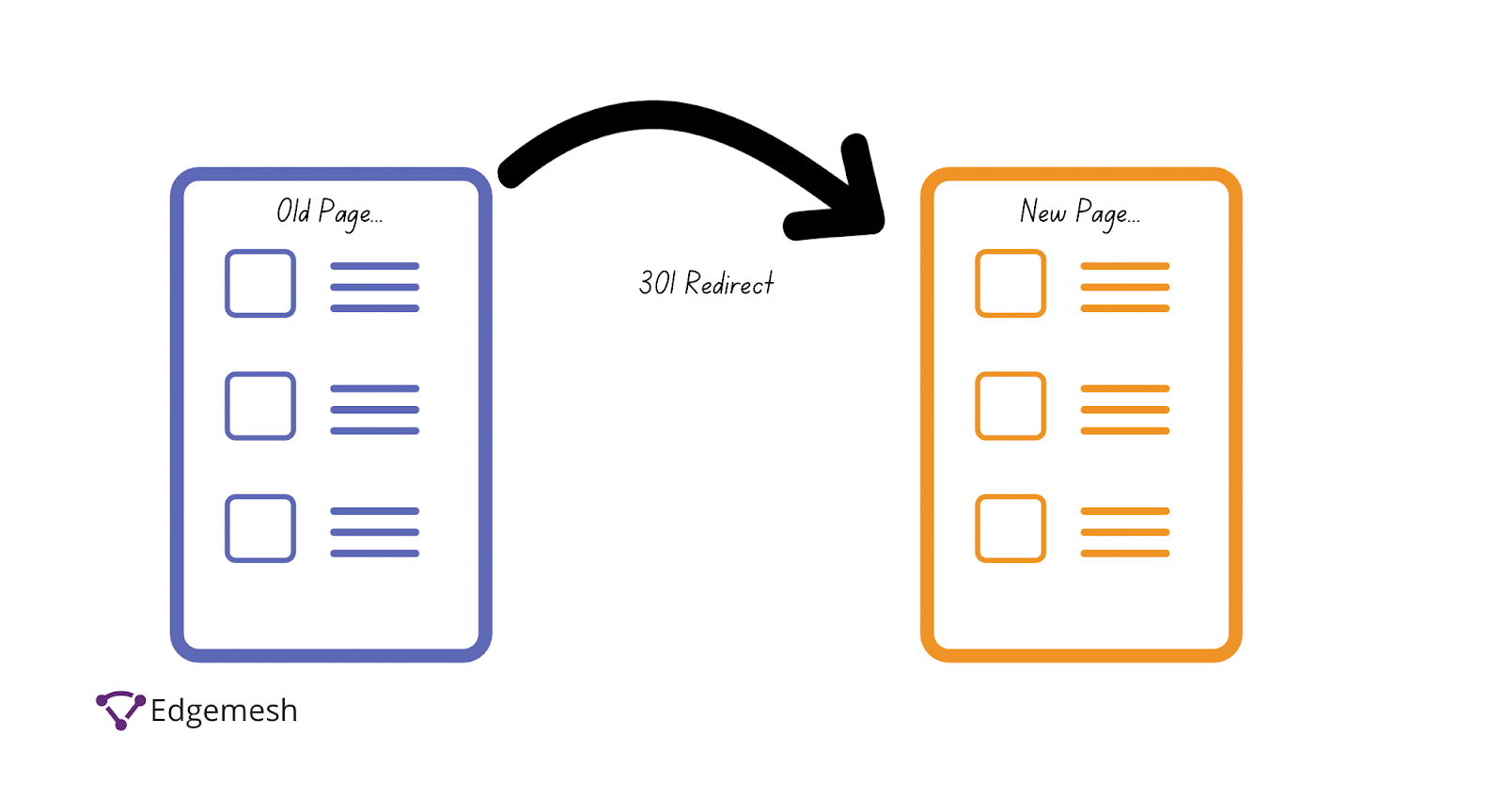
This is the best way to ensure Google and users are directed to the right page. In addition, the 301 redirect possesses a positive link value to your overall website performance in terms of SEO.
302 Redirect
The 302 redirect means the URL of the page is changed or moved temporarily—but the original will be back shortly.

This type of redirect is commonly used when running an A/B test on users, e.g., landing pages.
In most cases, you’ll confuse 301 and 302 redirects—and though they do almost the same thing, they serve different purposes.
One common difference: 301 is permanent, 302 is temporary. If you’re still going to re-use the URL at a later date, then a 302 redirect is good. And if not, then use the 301 redirects.
Side note: Google confirms 302 redirects pass a link value.
307 Redirect
The 307 redirect is the same as the 302 only difference is the HTTP method remains unchanged.
According to MDN Web Docs:
“HTTP 307 Temporary redirect indicates that the resource requested has been temporarily moved to the URL given the Location headers.”
4. Absence Of Domain Variations on Google Search Console
Domain variation is common on websites with sub-domain addresses pointing to the parent domain.
For example:
- Parent domain: example.com
- Sub-domain: blog.example.com
In most cases, your parent domain will be on the Google search console through your sitemap, but your subdomain wouldn’t. With the absence of your subdomain, Google is likely not to index your content even though it’s under the same parent—but not in the same root directory. The best solution is to submit the sitemap of this variant to Google and have the crawler do its job.
5. Poor Content Quality
This isn’t exactly an excuse for Google not crawling or indexing your website; instead, it’s more of a trust issue. If you have minimal or poor content quality on your website, Google will most likely put you at the bottom of the SERPs.
On one hand, Google is crawling and indexing your website. On the other, Google isn’t directing any traffic your way—so it feels like your website doesn’t exist since no one sees it.
When it comes to quality, long-form content performs better than short-form. The best solution for you here is to invest in writing content on your website—we’d advise a minimum of 1,500 words on every post.
Why do we suggest this? Google considers pages without enough content as “think websites”—and Google doesn’t rank those.
Wrapping Up
Google’s key to the right information is crawling and indexing billions of websites. A large concentration of that is focused on the hyperlinks of already crawled sites.
On the off-chance you don’t pop up on Google’s radar, put in the effort to put yourself in the right place to get indexed. An excellent way to benefit from this is to consider the architecture of your website and rank it based on the level of importance. The simpler your site architecture, the easier it’ll be for the Googlebot to crawl and index, not just your website but the right content, faster.
As you proceed, analyze all your pages consistently and check if any page isn’t indexed or is no longer indexed for different reasons. Overall, you have to position your website in a way to be found by search engines—unless you decide otherwise.
If you enjoyed this article, check out our blog for more articles on improving your website for better conversions and traffic.
Do customer experience, good conversions, low bounce rates, and overall speed matter to you? Then you’ll love Edgemesh’s Enterprise-Grade Web Acceleration.
Our intelligent, automated, and next-generation client-side caching readies your website to move at full speed—with just a single line of code. Plus, it takes under 5 minutes to set up.
What do you say?
Start your 14-day trial to get a feel for what speed means to your business.








